15.1 什么是例行性工作排程
每个人或多或少都有一些约会或者是工作,有的工作是例行性的,例如每年一次的加薪、每个月一次的工作报告、每周一次的午餐会报、每天需要的打卡等等; 有的工作则是临时发生的,例如刚好总公司有高官来访,需要你准备演讲器材等等! 用在生活上面,例如每年的爱人的生日、每天的起床时间等等、还有突发性的 3C 用品大降价等等。
像上面这些例行性工作,通常你得要记录在行事历上面才能避免忘记!不过,由于我们常常在计算机 前面的缘故, 如果计算机系统能够主动的通知我们的话,那么不就轻松多了!嘿嘿!这个时候 Linux 的例行性工作排程就可以派上场了! 在不考虑硬件与我们服务器的链接状态下,我们的 Linux 可以帮你提醒很多任务,例如:每一天早上 8:00 钟要服务器连接上音响,并启动音乐来唤你起床;而中 午 12:00 希望 Linux 可以发一封信到你的邮件信箱,提醒你可以去吃午餐了。
那么 Linux 的例行性工作是如何进行排程的呢?所谓的排程就是将这些工作安排执行的流程之意! 咱们的 Linux 排程就是透过crontab与at这两个东西!这两个玩意儿有啥异同?就让我们来瞧瞧先!
15.1.1 Linux 工作排程的种类:at,cron
从上面的说明当中,我们可以很清楚的发现两种工作排程的方式:
- 一种是例行性的,就是每隔一定的周期要来办的事项;
- 一种是突发性的,就是这次做完以后就没有的那一种;
那么在 Linux 底下如何达到这两个功能呢?那就得使用at与crontab这两个好东西!
- at :
at是个可以处理仅执行一次就结束排程的指令,不过要执行 - crontab :
crontab这个指令所设定的工作将会循环的一直进行下去! 可循环的时间为分钟、小时、每周、每月或每年等。crontab除了可以使用指令执行外,亦可编辑/etc/crontab来支持。 至于让crontab可以生 效的服务则是crond这个服务喔!
底下我们先来谈一谈 Linux 的系统到底在做什么事情,怎么有若干多的工作排程在进行呢?然后再回来谈一谈at与crontab这两个好东西!
15.1.2 Linux 系统上常见的例行性工作
如果你曾经使用过 Linux 一阵子了,那么你大概会发现到 Linux 会主动的帮我们进行一些工作呢! 比方说自动的进行在线更新 (on-line update)、自动的进行 updatedb (之前谈到的 locate 指令) 更新文件名数据库、自动的作登录档分析 (所以 root 常常会收到标题为 logwatch 的信件) 等等。这是由于系统要正常运作的话,某些在背景底下的工作必须要定时进行的缘故。基本上 Linux 系统常见的例行性任务有:
- 进行登录档的轮替 (log rotate):
Linux 会主动的将系统所发生的各种信息都记录下来,这就是登录档 (第十八章)。 由于系统会一直记录登录信息,所以登录文件将会越来越大!我们知道大型文件不但占容量还会造成读写效能的困扰,因此适时的将登录文件数据挪一挪,让旧的数据与新的数据分别存放,则比较可以有效的记录登录信息。这就是 log rotate 的任务!这也是系统必要的例行任务;
- 登录文件分析 logwatch 的任务:
如果系统发生了软件问题、硬件错误、资安问题等,绝大部分的错误信息都会被记录到登录文件中,因此系统管理员的重要任务之一就是分析登录档。但你不可能手动透过 vim 等软件去检视登录文件,因为数据 太复杂了! 我们的 CentOS 提供了一只程序logwatch来主动分析登录信息,所以你会发现,你的 root 老是会收到标题为 logwatch 的信件,那是正常的!你最好也能够看看该信件的内容!
- 建立 locate 的数据库:
在第六章我们谈到的 locate 指令时,我们知道该指令是透过已经存在的文件名数据库来进行系统上文件名的查询。我们的文件名数据库是放置到/var/lib/mlocate/中。问题是,这个数据库怎么会自动更新啊?这就是系统的例行性工作所产生的效果啦!系统会主动的进行 updatedb!
- man page 查询数据库的建立:
与 locate 数据库类似的,可提供快速查询的 man page db 也是个数据库,但如果要使用 man page 数据库时,就得要执行 mandb 才能够建立好啊! 而这个 man page 数据库也是透过系统的例行性工作排程来自动执行的哩!
- RPM 软件登录文件的建立:
RPM 是一种软件管理的机制。由于系统可能会常常变更软件,包括软件的新安装、非经常性更新等,都会造成软件文件名的差异。为了方便未来追踪,系统也帮我们将文件名作个排序的记录呢! 有时候系统也会透过排程来帮忙 RPM 数据库的重新建置!
- 移除暂存档:
某些软件在运作中会产生一些暂存档,但是当这个软件关闭时,这些暂存盘可能并不会主动的被移除。有些暂存盘则有时间性,如果超过一段时间后,这个暂存盘就没有效用了,此时移除这些暂存盘就是一件重要的工作!否则磁盘容量会被耗光。系统透过例行性工作排程执行名为 tmpwatch 的指令来删除这些暂存档呢!
- 与网络服务有关的分析行为:
如果你有安装类似 WWW 服务器软件 (一个名为 apache 的软件),那么你的 Linux 系统通常就会主动的分析该软件的登录文件。同时某些凭证与认证的网络信息是否过期的问题,我们的 Linux 系统也会很亲和的帮你进行自动检查!
其实你的系统会进行的例行性工作与你安装的软件多寡有关,如果你安装过多的软件,某些服务功能 的软件都会附上分析工具, 那么你的系统就会多出一些例行性工作.
15.2 仅执行一次的工作排程
首先,我们先来谈谈单一工作排程的运作,那就是 at 这个指令的运作!
15.2.1 atd 的启动与 at 运作的方式
要使用单一工作排程时,我们的 Linux 系统上面必须要有负责这个排程的服务,那就是atd这个玩意。不过并非所有的Linux distributions都预设会把他打开的,所以呢,某些时刻我们必须要手动将他启用才行。启用的方法很简单,就是这样:
[root@study xiaoqi]# systemctl restart atd <--重启atd服务
[root@study xiaoqi]# systemctl enable atd <--让这个服务开机自启
[root@study xiaoqi]# systemctl status atd <--查看atd服务运行状态
● atd.service - Job spooling tools
Loaded: loaded (/usr/lib/systemd/system/atd.service; enabled; vendor preset: enabled) <--是否开机自启
Active: active (running) since 五 2019-10-04 11:29:26 CST; 23s ago <--是否正在运行中
Main PID: 3701 (atd)
CGroup: /system.slice/atd.service
└─3701 /usr/sbin/atd -f
10月 04 11:29:26 study.centos.xiaoqi systemd[1]: Started Job spooling tools.
10月 04 11:29:26 study.centos.xiaoqi systemd[1]: Starting Job spooling tools...
重点就是要看到上表中的特殊字体,包括enabled以及running时,这才是atd真的有在运作的意思!
at 的运作方式
既然是工作排程,那么应该会有产生工作的方式,并且将这些工作排进行程表中啰!OK!那么产生工作的方式是怎么进行的? 事实上,我们使用 at 这个指令来产生所要运作的工作,并将这个工作以文本文件的方式写入 /var/spool/at/ 目录内,该工作便能等待 atd 这个服务的取用与执行了。就这么简单。
不过,并不是所有的人都可以进行 at 工作排程喔!为什么?因为安全的理由啊~ 很多主机被所谓 的『绑架』后,最常发现的就是他们的系统当中多了很多的怪客程序 (cracker program), 这些程序 非常可能运用工作排程来执行或搜集系统信息,并定时的回报给怪客团体! 所以啰,除非是你认可的账号,否则先不要让他们使用 at 吧!那怎么达到使用 at 的列管呢?
我们可以利用 /etc/at.allow 与 /etc/at.deny 这两个文件来进行 at 的使用限制呢! 加上这两个文件后, at 的工作情况其实是这样的:
- 先找寻 /etc/at.allow 这个文件,写在这个文件中的使用者才能使用 at ,没有在这个文件中的使用者则不能 使用 at (即使没有写在 at.deny 当中);
- 如果 /etc/at.allow 不存在,就寻找 /etc/at.deny 这个文件,若写在这个 at.deny 的使用者则不能使用 at , 而没有在这个 at.deny 文件中的使用者,就可以使用 at ;
- 如果两个文件都不存在,那么只有 root 可以使用 at 这个指令。
透过这个说明,我们知道 /etc/at.allow 是管理较为严格的方式,而 /etc/at.deny 则较为松散 (因为账号没有在该文件中,就能够执行 at 了)。在一般的 distributions 当中,由于假设系统上的所有用户都 是可信任的,因此系统通常会保留一个空的 /etc/at.deny 文件,意思是允许所有人使用 at 指令的意思 (您可以自行检查一下该文件)。 不过,万一你不希望有某些使用者使用 at 的话,将那个使用者的账号写入 /etc/at.deny 即可! 一个账号写一行。
15.2.2 实际运作单一工作排程
单一工作排程的进行就使用at这个指令啰!这个指令的运作非常简单!将at加上一个时间即可! 基本的语法如下:
[root@study ~]# at [-mldv] TIME
[root@study ~]# at -c 工作号码
选项与参数:
-m :当 at 的工作完成后,即使没有输出讯息,亦以 email 通知使用者该工作已完成。
-l :at -l 相当于 atq,列出目前系统上面的所有该用户的 at 排程;
-d :at -d 相当于 atrm ,可以取消一个在 at 排程中的工作;
-v :可以使用较明显的时间格式栏出 at 排程中的任务栏表;
-c :可以列出后面接的该项工作的实际指令内容。
TIME:时间格式,这里可以定义出『什么时候要进行 at 这项工作』的时间,格式有:
HH:MM ex> 04:00
在今日的 HH:MM 时刻进行,若该时刻已超过,则明天的 HH:MM 进行此工作。
HH:MM YYYY-MM-DD ex> 04:00 2015-07-30
强制规定在某年某月的某一天的特殊时刻进行该工作!
HH:MM[am|pm] [Month] [Date] ex> 04pm July 30
也是一样,强制在某年某月某日的某时刻进行!
HH:MM[am|pm] + number [minutes|hours|days|weeks]
ex> now + 5 minutes ex> 04pm + 3 days
就是说,在某个时间点『再加几个时间后』才进行。老实说,这个at指令的下达最重要的地方在于『时间』的指定了!喜欢使用now + ...的方式来定义现在过多少时间再进行工作,但有时也需要定义特定的时间点来进行!底下的范例先看看!
#范例一:再过五分钟后,将 /root/.bashrc 寄给 root 自己
[root@study xiaoqi]# at now + 5 minutes
at> /bin/mail -s "testing at job" root < /root/.bashrc
at> <EOT> <--这里输入 [ctrl] + d 就会出现 <EOF> 的字样!代表结束!
job 2 at Fri Oct 4 18:15:00 2019
#上面这行信息在说明,第 2 个 at 工作将在 2015/07/30 的 19:35 进行!
#而执行 at 会进入所谓的 at shell 环境,让你下达多重指令等待运作!
#范例二:将上述的第 2 项工作内容列出来查阅
[root@study xiaoqi]# at -c 2
#!/bin/sh
#atrun uid=0 gid=0
#mail xiaoqi 0
umask 22
......(省略部分变量)
cd /home/xiaoqi || {
echo 'Execution directory inaccessible' >&2
exit 1
}
${SHELL:-/bin/sh} << 'marcinDELIMITER761bd41c'
/bin/mail -s "testing at job" root < /root/.bashrc <--这行最重要
marcinDELIMITER761bd41c
#你可以看到指令执行的目录 (/root),还有多个环境变量与实际的指令内容啦!\
#范例三:由于机房预计于 2015/08/05 停电,我想要在 2015/08/04 23:00 关机?
[root@study xiaoqi]# at 18:17 2019-10-04
at> /bin/sync
at> /bin/sync
at> /sbin/shutdown -h now
at> <EOT>
job 3 at Fri Oct 4 18:17:00 2019
#您瞧瞧! at 还可以在一个工作内输入多个指令呢!很不错!事实上,当我们使用 at 时会进入一个 at shell 的环境来让用户下达工作指令,此时,建议你最好使用绝对路径来下达你的指令,比较不会有问题喔!由于指令的下达与 PATH 变量有关, 同时与当时的工作目录也有关连 (如果有牵涉到文件的话),因此使用绝对路径来下达指令,会是比较一劳永逸的方法。为什么呢?举例来说,你在 /tmp 下达 at now 然后输入mail -s "test" root < .bashrc, 问一下,那个 .bashrc 的文件会是在哪里?答案是 /tmp/.bashrc!因为 at 在运作时,会跑到当时下达 at 指令的那个工作目录的缘故!
有些朋友会希望『我要在某某时刻,在我的终端机显示出 Hello 的字样』,然后就在 at 里面下达这 样的信息echo "Hello"』。等到时间到了,却发现没有任何讯息在屏幕上显示,这是啥原因啊? 这是因为 at 的执行与终端机环境无关,而所有 standard output/standard error output 都会传送到执行者的 mailbox 去啦!所以在终端机当然看不到任何信息。那怎办?没关系,可以透过终端机的装置来处理!假如你在 tty1 登入,则可以使用 echo "Hello" > /dev/tty1 来取代。
要注意的是,如果在 at shell 内的指令并没有任何的讯息输出,那么 at 默认不会发 email 给执行者的。 如果你想要让 at 无论如何都发一封 email 告知你是否执行了指令,那么可以使用『 at -m 时间格式 』来下达指令喔! at 就会传送一个讯息给执行者,而不论该指令执行有无讯息输出了!
at 有另外一个很棒的优点,那就是『背景执行』的功能了!什么是背景执行啊?很难了解吗?其实与 bash 的 nohup 类似!
由于 at 工作排程的使用上,系统会将该项 at 工作独立出你的 bash 环境中,直接交给系统的 atd 程序来接管,因此,当你下达了 at 的工作之后就可以立刻脱机了,剩下的工作就完全交给 Linux 管理即可!
15.2.3 at 工作的管理
那么万一我下达了at之后,才发现指令输入错误,该如何是好?就将他移除啊!利用atq与atrm !
[root@study xiaoqi]# atq
[root@study ~]# atrm (jobnumber)
#范例一:查询目前主机上面有多少的 at 工作排程?
[root@study xiaoqi]# atq
6 Sun Oct 6 22:25:00 2019 a root
#上面说的是:『在 2019-10-06 的 22:25 有一项工作,该项工作指令下达者为 # root』
#而且,该项工作的工作号码 (jobnumber) 为 6 号!
#范例二:将上述的第 3 个工作移除!
[root@study xiaoqi]# atrm 6 <--jobnumber号码
[root@study xiaoqi]# atq
#没有任何信息,表示该工作被移除了!
如此一来,你可以利用 atq 来查询,利用 atrm 来删除错误的指令,利用 at 来直接下达单一工作排程!很简单吧!不过,有个问题需要处理一下。如果你是在一个非常忙碌的系统下运作 at ,能不能指定你的工作在系统较闲的时候才进行呢?可以的,那就使用 batch 指令!
15.2.4 batch:系统无负载后进行背景任务
其实 batch 是利用 at 来进行指令的下达啦!只是加入一些控制参数而已。这个 batch 神奇的地方在于:他会在 CPU 的工作负载小于 0.8 的时候,才进行你所下达的工作任务啦!那什么是工作负载0.8 呢?这个工作负载的意思是: CPU 在单一时间点所负责的工作数量。不是 CPU 的使用率喔! 举例来说,如果我有一只程序他需要一直使用 CPU 的运算功能,那么此时 CPU 的使用率可能到达 100% ,但是 CPU 的工作负载则是趋近于『 1 』,因为 CPU 仅负责一个工作!如果同时执行两个这样的程序? CPU 的使用率还是 100% ,但是工作负载则变成 2 了!
所以也就是说,当 CPU 的工作负载越大,代表 CPU 必须要在不同的工作之间进行频繁的工作切换。因为一直切换工作,所以会导致系统忙碌! 系统如果很忙碌,还要额外进行 at 不太合理!所以才有 batch 指令的产生!
在 CentOS 7 底下的 batch 已经不再支持时间参数了,因此 batch 可以拿来作为判断是否要立刻执行背景程序的依据! 我们底下来实验一下 batch 好了!为了产生 CPU 较高的工作负载,因此我们用了计算 pi 的脚本,连续执行 4 次这只程序,来仿真高负载,然后来玩一玩 batch 的工作现象:
#范例一:执行 pi 的计算,然后在系统闲置时,执行 updatdb 的任务
[study@xiaoqi ~]$ echo "scale=100000; 4*a(1)" | bc -lq &
[study@xiaoqi ~]$ echo "scale=100000; 4*a(1)" | bc -lq &
[study@xiaoqi ~]$ echo "scale=100000; 4*a(1)" | bc -lq &
[study@xiaoqi ~]$ echo "scale=100000; 4*a(1)" | bc -lq &
#过个十几秒后执行uptime查看cpu负载
[study@xiaoqi ~]$ uptime
19:06:36 up 13 min, 1 user, load average: 4.14, 2.66, 1.28
[study@xiaoqi ~]$ batch
at> /usr/bin/updatedb
at> <EOT>
[study@xiaoqi ~]$ date;atq
2019年 10月 08日 星期二 22:35:09 CST
3 Tue Oct 8 22:32:00 2019 b study
#可以看得到,明明时间已经超过了,却没有实际执行 at 的任务!
[study@xiaoqi ~]$ jobs
[1] 运行中 echo "scale=100000; 4*a(1)" | bc -lq &
[2] 运行中 echo "scale=100000; 4*a(1)" | bc -lq &
[3]- 运行中 echo "scale=100000; 4*a(1)" | bc -lq &
[4]+ 运行中 echo "scale=100000; 4*a(1)" | bc -lq &
[study@xiaoqi ~]$ kill -9 %1 %2 %3 %4
#这时先用 jobs 找出背景工作,再使用 kill 删除掉四个背景工作后,慢慢等待工作负载的下降
[study@xiaoqi ~]$ uptime
22:38:16 up 3:44, 1 user, load average: 2.63, 2.62, 1.31
[1] 已杀死 echo "scale=100000; 4*a(1)" | bc -lq
[2] 已杀死 echo "scale=100000; 4*a(1)" | bc -lq
[3]- 已杀死 echo "scale=100000; 4*a(1)" | bc -lq
[4]+ 已杀死 echo "scale=100000; 4*a(1)" | bc -lq
[study@xiaoqi ~]$ uptime;atq
22:40:39 up 3:47, 1 user, load average: 1.32, 1.65, 1.13
3 Tue Oct 8 22:32:00 2019 b study
[study@xiaoqi ~]$ uptime;atq
22:44:04 up 3:50, 1 user, load average: 0.09, 0.85, 0.91
#在 10:42 时,由于 loading 还是高于 0.8,因此 atq 可以看得到 at job 还是持续再等待当中喔!
#但是到了 22:40 时, loading 降低到 0.8 以下了,所以 atq 就执行完毕啰!使用 uptime 可以观察到 1, 5, 15 分钟的『平均工作负载』量,因为是平均值,所以当我们如上表删除掉四个工作后,工作负载不会立即降低, 需要一小段时间让这个 1 分钟平均值慢慢回复到接近 0 啊!当小于 0.8 之后的『整分钟时间』时,atd 就会将 batch 的工作执行掉了!
什么是『整分钟时间』呢?不论是 at 还是底下要介绍的 crontab,他们最小的时间单位是『分钟』, 所以,基本上,他们的工作是『每分钟检查一次』来处理的! 就是整分 (秒为 0 的时候),同时,你会发现其实 batch 也是使用 atq/atrm 来管理的!
15.3 循环执行的例行性工作排程
相对于at是仅执行一次的工作,循环执行的例行性工作排程则是由cron(crond)这个系统服务来控制的。刚刚谈过 Linux 系统上面原本就有非常多的例行性工作,因此这个系统服务是默认启动的。另外,由于使用者自己也可以进行例行性工作排程,所以啰,Linux 也提供使用者控制例行性工作排程的指令crontab。底下我们分别来聊一聊!
15.3.1 使用者的设定
使用者想要建立循环型工作排程时,使用的是 crontab 这个指令~不过,为了安全性的问题,与at同样的,我们可以限制使用 crontab 的使用者账号!使用的限制数据有:
- /etc/cron.allow:
将可以使用 crontab 的账号写入其中,若不在这个文件内的使用者则不可使用 crontab;- /etc/cron.deny:
将不可以使用 crontab 的账号写入其中,若未记录到这个文件当中的使用者,就可以使用 crontab。与 at 很像!同样的,以优先级来说,/etc/cron.allow 比 /etc/cron.deny 要优先,而判断上面,这两个文件只选择一个来限制而已,因此,建议你只要保留一个即可,免得影响自己在设定上面的判断!一般来说,系统默认是保留 /etc/cron.deny,你可以将不想让他执行crontab的那个使用者写 入 /etc/cron.deny 当中,一个账号一行!
当用户使用crontab这个指令来建立工作排程之后,该项工作就会被纪录到/var/spool/cron/里面去了,而且是以账号来作为判别的!举例来说,xiaoqi 使用crontab后,他的工作会被纪录到/var/spool/cron/xiaoqi里头去!但请注意,不要使用vi直接编辑该文件,因为可能由于输入语法错误,会导致无法执行cron喔!另外,cron执行的每一项工作都会被纪录到/var/log/cron这个登录档中,所以,如果你的 Linux 不知道有否被植入木马时,也可以搜寻一下/var/log/cron这个文件内!
- 好了,那么我们就来聊一聊
crontab的语法:
[root@study ~]# crontab [-u username] [-l|-e|-r]
选项与参数:
-u :只有 root 才能进行这个任务,亦即帮其他使用者建立/移除 crontab 工作排程;
-e :编辑 crontab 的工作内容
-l :查阅 crontab 的工作内容
-r :移除所有的 crontab 的工作内容,若仅要移除一项,请用 -e 去编辑。
#范例一:用xiaoqi的身份在每天12:00发信息给自己
[xiaoqi@xiaoqi ~]$ crontab -e
#此时会进入 vi 的编辑画面让您编辑工作!注意到,每项工作都是一行。
0 12 * * * mail -s "at 12:00 xiaoqi < /home/xiaoqi/.bashrc"
分 时 日 月 周 |<--------------------指令串------------------->|预设情况下,任何使用者只要不被列入/etc/cron.deny当中,那么他就可以直接下达crontab -e去编辑自己的例行性命令了!整个过程就如同上面提到的,会进入 vi 的编辑画面,然后以一个工作一行来编辑,编辑完毕之后输入:wq储存后离开 vi 就可以了!而每项工作(每行)的格式都是具有六个字段,这六个字段的意义为:
| 代表意义 | 分钟 | 小时 | 日期 | 月份 | 周 | 指令 |
|---|---|---|---|---|---|---|
| 数字范围 | 0-59 | 0-23 | 1-31 | 1-12 | 0-7 | 执行的指令 |
比较有趣的是那个周!周的数字为0或7时,都代表『星期天』的意思!另外,还有一些辅助的字符,大概有底下这些:
| 特殊字符 | 代表意义 |
|---|---|
| *(星号) | 代表任何时刻都接受的意思!举例来说,范例一内那个日、月、周都是*,就代表着不论何月、何日的礼拜几的 12:00 都执行后续指令的意思! |
| ,(逗号) | 代表分隔时段的意思。举例来说,如果要下达的工作是3:00与6:00时,就会是:0 3,6 * * * command时间参数还是有五栏,不过第二栏是3,6,代表 3 与 6 都适用! |
| -(减号) | 代表一段时间范围内,举例来说,8 点到 12 点之间的每小时的 20 分都进行一项工作:20 8-12 * * * command仔细看到第二栏变成 8-12!代表 8,9,10,11,12 都适用的意思! |
| /n(斜线) | 那个 n 代表数字,亦即是每隔 n 单位间隔的意思,例如每五分钟进行一次,则:*/5 * * * * command很简单吧!用 * 与 /5 来搭配,也可以写成 0-59/5 ,相同意思! |
我们就来搭配几个例子练习看看!底下的案例请实际用 xiaoqi 这个身份作看看!后续的动作才能够搭配起来!
例题:
假若你的女朋友生日是 5 月 2 日,你想要在 5 月 1 日的 23:59 发一封信给他,这封信的内容已经写在 /home/xiaoqi/lover.txt 内了,该如何进行?
答:
直接下达 crontab -e 之后,编辑成为
59 23 1 5 * mail kiki < /home/xiaoqi/lover.txt
那样的话,每年 kiki 都会收到你的这封信!(当然,信的内容就要每年变一变了!)
例题:
假如每五分钟需要执行 /home/xiaoqi/test.sh 一次,又该如何?
答:
同样使用 crontab -e 进入编辑:
*/5 * * * * /home/xiaoqi/test.sh那个 crontab 每个人都只有一个文件存在,就是在 /var/spool/cron 里面啊! 还有建议:『指令下达时,最好使用绝对路径,这样比较不会找不到执行文件!』
那么,该如何查询使用者目前的 crontab 内容呢?我们可以这样来看看:
[dmtsai@study ~]$ crontab -l
0 12 * * * mail -s "at 12:00" xiaoqi < /home/xiaoqi/.bashrc
59 23 1 5 * mail kiki < /home/xiaoqi/lover.txt
*/5 * * * * /home/xiaoqi/test.sh
30 16 * * 5 mail friend@his.server.name < /home/xiaoqi/friend.txt
#注意,若仅想要移除一项工作而已的话,必须要用 crontab -e 去编辑~
#如果想要全部的工作都移除,才使用 crontab -r !
[root@study ~]# crontab -l
*/1 * * * * /bin/echo $(date) >> /dev/pts/0
[root@study ~]# crontab -r
[root@study ~]# crontab -l
no crontab for root看到了吗? crontab 『整个内容都不见了!』所以请注意:『如果只是要删除某个 crontab 的工作项目,那么请使用 crontab -e 来重新编辑即可!』如果使用 -r 的参数,是会将所有的 crontab 数据内容都删掉的!
15.3.2 系统的配置文件:
/etc/crontab
这个crontab -e是针对使用者的 cron 来设计的,如果是『系统的例行性任务』时,该怎么办呢?是否还是需要以 crontab -e 来管理你的例行性工作排程呢?当然不需要,你只要编辑 /etc/crontab 这个文件就可以啦!有一点需要特别注意喔!那就是 crontab -e` 这个 crontab 其实是 /usr/bin/crontab 这个执行档,但是 /etc/crontab 可是一个『纯文本档』!你可以 root 的身份编辑一下这个文件!
基本上,cron 这个服务的最低侦测限制是『分钟』,所以『 cron 会每分钟去读取一次 /etc/crontab 与 /var/spool/cron 里面的数据内容 』,因此,只要你编辑完 /etc/crontab 这个文件,并且将他储存之后, 那么 cron 的设定就自动的会来执行了!
在 Linux 底下的 crontab 会自动的帮我们每分钟重新读取一次/etc/crontab的例行工 作事项,但是某些原因或者是其他的 Unix 系统中,由于 crontab 是读到内存当中的,所以在你修改完/etc/crontab之后,可能并不会马上执行, 这个时候请重新启动 crond 这个服务吧!『systemctl restart crond』
- 我们就来看一下这个
/etc/crontab的内容:
[root@study screenFetch-master]# cat /etc/crontab
SHELL=/bin/bash <--使用的shell接口
PATH=/sbin:/bin:/usr/sbin:/usr/bin <--执行文件的搜寻路径
MAILTO=root <--若有额外 STDOUT,以 email 将数据送给谁
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed看到这个文件的内容你大概就了解了吧!这个文件与将刚刚我们下达 crontab -e 的内容几乎完全一模一样!只是有几个地方不太相同:
- MAILTO=root:
这个项目是说,当 /etc/crontab 这个文件中的例行性工作的指令发生错误时,或者是该工作的执行 结果有 STDOUT/STDERR 时,会将错误讯息或者是屏幕显示的讯息传给谁?默认当然是由系统 直接寄发一封 mail 给 root !不过,由于 root 并无法在客户端中以 POP3 之类的软件收信,因此,通常都将这个 e-mail 改成自己的账号,好让我随时了解系统的状况!例如:MAILTO=xiaoqi@my.host.name
- PATH=....:
这里就是输入执 行文件的搜寻路径!使用默认的路径设定就已经很足够了!
分 时 日 月 周 身份 指令七个字段的设定:
这个 /etc/crontab 里面可以设定的基本语法与 crontab -e 不太相同!前面同样是分、时、日、月、 周五个字段,但是在五个字段后面接的并不是指令,而是一个新的字段,那就是『执行后面那串指令的身份』为何!这与使用者的 crontab -e 不相同。由于使用者自己的 crontab 并不需要指定身份,但 /etc/crontab 里面当然要指定身份啦!以上表的内容来说,系统默认的例行性工作是以 root 的身份来进行的。
/etc/cron.d/*
- crond 服务读取配置文件的位置
一般来说,crond 预设有三个地方会有执行脚本配置文件,他们分别是:
- /etc/crontab
- /etc/cron.d/*
- /var/spool/cron/*
这三个地方中,跟系统的运作比较有关系的两个配置文件是放在 /etc/crontab 文件内以及/etc/cron.d/* 目录内的文件,另外一个是跟用户自己的工作比较有关的配置文件,就是放在 /var/spool/cron/ 里面的文件群。现在我们已经知道了 /var/spool/cron 以及 /etc/crontab 的内容,那现在来瞧瞧 /etc/cron.d 里面的东西!
[root@study ~]# ls -l /etc/cron.d/
总用量 12
-rw-r--r--. 1 root root 128 7月 27 2015 0hourly
-rw-r--r--. 1 root root 108 9月 18 2015 raid-check
-rw-------. 1 root root 235 3月 6 2015 sysstat
#其实说真的,除了 /etc/crontab 之外,crond 的配置文件还不少!上面就有三个设定!
#先让我们来瞧瞧 0hourly 这个配置文件的内容!
[root@study ~]# cat /etc/cron.d/0hourly
# Run the hourly jobs
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
01 * * * * root run-parts /etc/cron.hourly
#内容跟 /etc/crontab 几乎一模一样!但实际上是有设定值!就是最后一行!如果你想要自己开发新的软件,该软件要拥有自己的 crontab 定时指令时,就可以将分、时、日、 月、周、身份、指令的配置文件放置到 /etc/cron.d/ 目录下! 在此目录下的文件是『crontab 的配置文件脚本』。
关于/etc/cron.*的配置文件
请注意一下上面表格中提到的最后一行,每个整点的一分会执行run-parts /etc/cron.hourly这个指令是什么意识?什么是 run-parts 呢?
如果你有去分析一下这个执行档,会发现他就是shell script,run-parts脚本会在大约 5 分钟内随机选一个时间来执行/etc/cron.hourly目录内的所有执行文件!因此,放在 /etc/cron.hourly/的文件,必须是能被直接执行的指令脚本,而不是分、时、日、月、周 的设定值!注意注意!
也就是说,除了自己指定分、时、日、月、周加上指令路径的 crond 配置文件之外,你也可以直接将指令放置到(或链接到)/etc/cron.hourly/ 目录下,则该指令就会被 crond 在每小时的 1 分开始后的 5 分钟内,随机取一个时间点来执行!你无须手动去指定分、时、日、月、周就是了。
除了可以直接将指令放到 /etc/cron.hourly/ 让系统每小时定时执行之外,在 /etc/ 底下其实还有 /etc/cron.daily/, /etc/cron.weekly/,/etc/cron.monthly/,那三个目录是代表每日、每周、每月各执行一次的意思.不过,跟 /etc/cron.hourly/ 不太一样的是,那三个目录是由 anacron 所执行的,而 anacron 的执行方式则是放在/etc/cron.hourly/0anacron里面~跟前几代 anacron 是单独的 service 不太一样喔!
总结例行工作最佳建立方式:
- 个人化的行为使用『crontab-e』:如果你是依据个人需求来建立的例行工作排程,建议直接使用crontab -e 来建立你的工作排程较佳! 这样也能保障你的指令行为不会被大家看到 (/etc/crontab 是大家都能读取的权限喔!);
- 系统维护管理使用『 vim /etc/crontab 』:如果你这个例行工作排程是系统的重要工作,为了让自己管理方便,同时容易追踪,建议直接写入 /etc/crontab 较佳!
- 自己开发软件使用『 vim /etc/cron.d/newfile 』:如果你是想要自己开发软件,那当然最好就是使用全新的配置文件,并且放置于 /etc/cron.d/ 目录内即可。
- 固定每小时、每日、每周、每天执行的特别工作:如果与系统维护有关,还是建议放置到
/etc/crontab中来集中管理较好。如果想要偷懒,或者是一定要再某个周期内进行的任务,也可以放置到上面谈到的几个目录中,直接写入指令即可!
15.3.3 一些注意事项
有的时候,我们以系统的 cron 来进行例行性工作的建立时,要注意一些使用方面的特性。举例来说,如果我们有四个工作都是五分钟要进行一次的,那么是否这四个动作全部都在同一个时间点进行? 如果同时进行,该四个动作又很耗系统资源,如此一来,每五分钟的某个时刻不是会让系统忙得要死? 此时好好的分配一些运行时间就 OK 啦!所以,注意一下:
- 资源分配不均的问题
当大量使用 crontab 的时候,总是会有问题发生的,最严重的问题就是『系统资源分配不均』的问题, 以测试的系统为例,我有侦测主机流量的信息,包括:流量,区域内其他 PC 的流量侦测,CPU 使用率,RAM 使用率,在线人数实时侦测
如果每个流程都在同一个时间启动的话,那么在某个时段时,我的系统会变的相当的繁忙,所以,这个时候就必须要分别设定啦!我可以这样做:
[root@study ~]# vim /etc/crontab
1,6,11,16,21,26,31,36,41,46,51,56 * * * * root CMD1
2,7,12,17,22,27,32,37,42,47,52,57 * * * * root CMD2
3,8,13,18,23,28,33,38,43,48,53,58 * * * * root CMD3
4,9,14,19,24,29,34,39,44,49,54,59 * * * * root CMD4那个,分隔的时候,请注意,不要有空格符!(连续的意思)如此一来,则可以将每五分钟工作的流程分别在不同的时刻来工作!则可以让系统的执行较为顺畅!
- 取消不要的输出项目
另外一个困扰发生在当有执行成果或者是执行的项目中有输出的数据时,该数据将会 mail 给 MAILTO 设定的账号,好啦,那么当有一个排程一直出错(例如 DNS 的侦测系统当中,若 DNS 上层主机挂掉,那么你就会一直收到错误讯息!)怎么办?可以直接以『数据流重导向』将输出的结果输出到 /dev/null 这个垃圾桶当中就好了!
- 安全的检验
很多时候被植入木马都是以例行命令的方式植入的,所以可以藉由检查 /var/log/cron 的内容来视察是否有『非您设定的 cron 被执行了?』这个时候就需要小心一点!
- 周与日月不可同时并存
另一个需要注意的地方在于:『你可以分别以周或者是日月为单位作为循环,但你不可使用「几月几 号且为星期几」的模式工作』。这个意思是说,你不可以这样编写一个工作排程:
30 12 11 9 5 root echo "just test" <==这是错误的写法本来你以为九月十一号且为星期五才会进行这项工作,无奈的是,系统可能会判定每个星期五作一次, 或每年的 9 月 11 号分别进行,如此一来与你当初的规划就不一样了~所以,得要注意这个地方!
根据某些人的说法,这个月日、周不可并存的问题已经在新版中被修复了~不过,并没有实际去验证他!目前也不打算验证他! 因为,周就是周,月日就月日,单一执行点就单一执行点,无须使用 crontab 去设定固定的日期!
15.4 可唤醒停机期间的工作任务
想象一个环境,你的 Linux 服务器有一个工作是需要在每周的星期天凌晨 2 点进行,但是很不巧的,星期六停电了~所以你得要星期一才能进公司去启动服务器。那么请问,这个星期天的工作排程还要不要进行?因为你开机的时候已经是星期一,所以星期天的工作当然不会被进行,对吧!
问题是,若是该工作非常重要 (例如例行备份), 所以其实妳还是希望在下个星期天之前的某天还是进行一下比较好~那你该怎办?自己手动执行?如果你跟我一样是个记忆力超差的家伙,那么肯定『记不起来某个重要工作要进行』! 这时候就得要靠 anacron 这个指令的功能了!这家指令可以 主动帮你进行时间到了但却没有执行的排程!
14.4.1什么是 anacron
anacron 并不是用来取代 crontab 的,anacron 存在的目的就在于我们上头提到的,在处理非 24 小 时一直启动的 Linux 系统的 crontab 的执行!以及因为某些原因导致的超过时间而没有被执行的排 程工作。
其实 anacron 也是每个小时被 crond 执行一次,然后 anacron 再去检测相关的排程任务有没有被执行,如果有超过期限的工作在, 就执行该排程任务,执行完毕或无须执行任何排程时,anacron 就停止了。
由于 anacron 预设会以一天、七天、一个月为期去侦测系统未进行的 crontab 任务,因此对于某些特殊的使用环境非常有帮助。举例来说,如果你的 Linux 主机是放在公司给别人使用的,因为周末假日大家都不在所以也没有必要开启,因此你的 Linux 是周末都会关机两天的。但是 crontab 大多在每天的凌晨以及周日的早上进行各项任务,偏偏你又关机了,此时系统很多 crontab 的任务就无法进行。 anacron 刚好可以解决这个问题!
那么 anacron 又是怎么知道我们的系统啥时关机的呢?这就得要使用 anacron 读取的时间记录文件 (timestamps) 了! anacron 会去分析现在的时间与时间记录文件所记载的上次执行 anacron 的时间,两者比较后若发现有差异,那就是在某些时刻没有进行 crontab !此时 anacron 就会开始执行未进行的 crontab 任务了!
14.4.2 anacron 与 /etc/anacrontab
anacron 其实是一个程序并非一个服务!这个程序在 CentOS 当中已经进入 crontab 的排程!同时 anacron 会每个小时被主动执行一次!每个小时?所以 anacron 的配置文件应该放置在 /etc/cron.hourly.赶紧来瞧一瞧:
[root@study ~]# cat /etc/cron.hourly/0anacron
#!/bin/sh
# Check whether 0anacron was run today already
if test -r /var/spool/anacron/cron.daily; then
day=`cat /var/spool/anacron/cron.daily`
fi
if [ `date +%Y%m%d` = "$day" ]; then
exit 0;
fi
# 上面的语法在检验前一次执行 anacron 时的时间戳
# Do not run jobs when on battery power
if test -x /usr/bin/on_ac_power; then
/usr/bin/on_ac_power >/dev/null 2>&1
if test $? -eq 1; then
exit 0
fi
fi
/usr/sbin/anacron -s
# 所以其实也仅是执行 anacron -s 的指令!因此我们得来谈谈这个程序!- 基本上, anacron 的语法如下:
[root@study ~]# anacron [-sfn] [job]..
[root@study ~]# anacron -u [job]..
选项与参数:
-s :开始一连续的执行各项工作 (job),会依据时间记录文件的数据判断是否进行;
-f :强制进行,而不去判断时间记录文件的时间戳;
-n :立刻进行未进行的任务,而不延迟 (delay) 等待时间;
-u :仅更新时间记录文件的时间戳,不进行任何工作。
job :由 /etc/anacrontab 定义的各项工作名称。在我们的 CentOS 中,anacron的进行其实是在每个小时都会被抓出来执行一次,但是为了担心anacron误判时间参数,因此 /etc/cron.hourly/ 里面的 anacron 才会在档名之前加个 0 (0anacron),让 anacron 最先进行!就是为了让时间戳先更新!以避免 anacron 误判 crontab 尚未进行任何工作的意思。
- 接下来我们看一下 anacron 的配置文件:
/etc/anacrontab的内容好:
[root@study ~]# cat /etc/anacrontab
# /etc/anacrontab: configuration file for anacron
# See anacron(8) and anacrontab(5) for details.
SHELL=/bin/sh
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# the maximal random delay added to the base delay of the jobs
RANDOM_DELAY=45 <--随机给予最大延迟时间,单位是分钟
# the jobs will be started during the following hours only
START_HOURS_RANGE=3-22 <--延迟多少个小时内应该要执行的任务时间
#period in days delay in minutes job-identifier command
1 5 cron.daily nice run-parts /etc/cron.daily
7 25 cron.weekly nice run-parts /etc/cron.weekly
@monthly 45 cron.monthly nice run-parts /etc/cron.monthly
#天数 延迟时间 工作名称定义 实际要进行的指令串
#天数单位为天;延迟时间单位为分钟;工作名称定义可自定义,指令串则通常与 crontab 的设定相同!
[root@study ~]# more /var/spool/anacron/*
::::::::::::::
/var/spool/anacron/cron.daily
::::::::::::::
20191012
::::::::::::::
/var/spool/anacron/cron.monthly
::::::::::::::
20191011
::::::::::::::
/var/spool/anacron/cron.weekly
::::::::::::::
20191009
#上面则是三个工作名称的时间记录文件以及记录的时间戳我们拿 /etc/cron.daily/ 那一行的设定来说明好了。那四个字段的意义分别是:
- 天数:anacron 执行当下与时间戳 (/var/spool/anacron/ 内的时间纪录文件) 相差的天数,若超过此天数,就准备开始执行,若没有超过此天数,则不予执行后续的指令。
- 延迟时间:若确定超过天数导致要执行排程工作了,那么请延迟执行的时间,因为担心立即启动会有其他资源冲突的问题吧!
- 工作名称定义:这个没啥意义,就只是会在 /var/log/cron 里头记载该项任务的名称这样!通常与后续的目录资源名称相同即可。
- 实际要进行的指令串:有没有跟 0hourly 很像啊!没错!相同的作法啊!透过 run-parts 来处理的!
根据上面的配置文件内容,我们大概知道 anacron 的执行流程应该是这样的 (以 cron.daily 为例):
- 由 /etc/anacrontab 分析到 cron.daily 这项工作名称的天数为 1 天;
- 由 /var/spool/anacron/cron.daily 取出最近一次执行 anacron 的时间戳;
- 由上个步骤与目前的时间比较,若差异天数为 1 天以上 (含 1 天),就准备进行指令;
- 若准备进行指令,根据 /etc/anacrontab 的设定,将延迟 5 分钟 + 3 小时 (看 START_HOURS_RANGE 的设定);
- 延迟时间过后,开始执行后续指令,亦即『 run-parts /etc/cron.daily 』这串指令;
- 执行完毕后, anacron 程序结束。
如此一来,放置在 /etc/cron.daily/ 内的任务就会在一天后一定会被执行的!因为 anacron 是每个小时被执行一次! 所以,现在你知道为什么隔了一阵子才将 CentOS 开机,开机过后约 1 小时左右系统会有一小段时间的忙碌!而且硬盘会跑个不停!那就是因为 anacron 正在执行过去/etc/cron.daily/, /etc/cron.weekly/, /etc/cron.monthly/ 里头的未进行的各项工作排程!
14.2.3 总结crond 与 anacron 的关系:
- crond 会主动去读取 /etc/crontab, /var/spool/cron/*, /etc/cron.d/* 等配置文件,并依据『分、时、日、月、周』 的时间设定去各项工作排程;
- 根据 /etc/cron.d/0hourly 的设定,主动去 /etc/cron.hourly/ 目录下,执行所有在该目录下的执行文件;
- 因为 /etc/cron.hourly/0anacron 这个脚本文件的缘故,主动的每小时执行 anacron ,并呼叫 /etc/anacrontab的配置文件;
- 根据 /etc/anacrontab 的设定,依据每天、每周、每月去分析 /etc/cron.daily/, /etc/cron.weekly/, /etc/cron.monthly/内的执行文件,以进行固定周期需要执行的指令。
也就是说,如果你每个周日的需要执行的动作是放置于 /etc/crontab 的话,那么该动作只要过期了就过期了,并不会被抓回来重新执行。但如果是放置在 /etc/cron.weekly/ 目录下,那么该工作就会定期, 几乎一定会在一周内执行一次~如果你关机超过一周,那么一开机后的数个小时内,该工作就会主动的被执行!
- 基本上,crontab 与 at 都是『定时』去执行,过了时间就过了!不会重新来一遍~那 anacron 则是『定期』去执行,某一段周期的执行~ 因此,两者可以并行,并不会互相冲突!
Cron和Anacrontab关系图
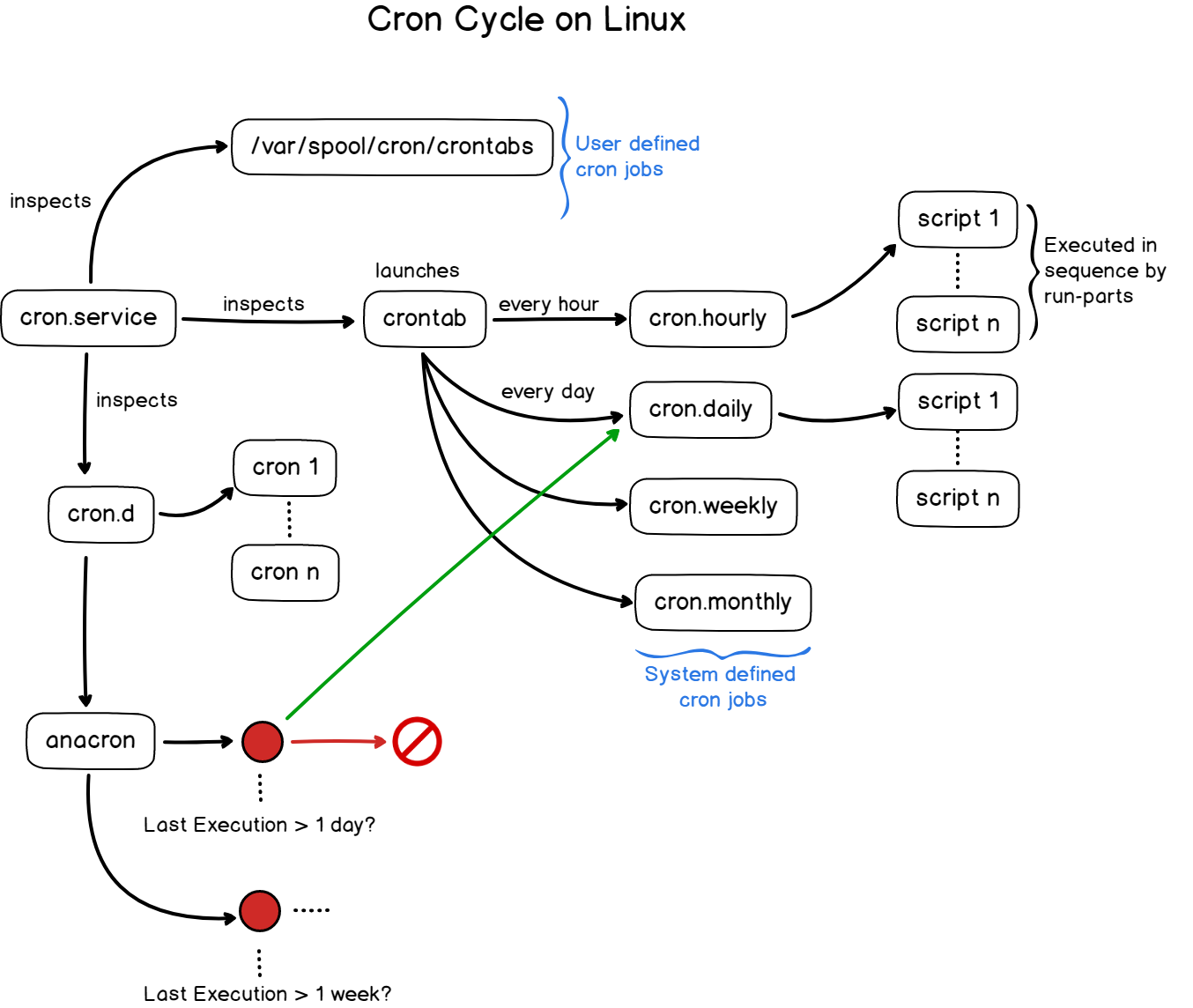
版权属于:龙之介大人
本文链接:https://i7dom.cn/179/2019/13/linux-cron-cycle.html
本站所有原创文章采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 您可以自由的转载和修改,但请务必注明文章来源和作者署名并说明文章非原创且不可用于商业目的。